
Związek bez relacji ? nierelacyjne bazy danych (NoSQL) . Część 2 ? poszczególne typy nierelacyjnych baz danych.

Jak zostało to opisane już w części 1 (dostępnej pod adresem: CZĘŚCI 1), nierelacyjne bazy danych można podzielić na kilka kategorii (pod kątem modelu danych):
- Klucz ? wartość
- Dokument
- Graf
- Rodzina kolumn
Poniższy artykuł przedstawia krótką charakterystykę każdej z nich. Dla pełniejszego obrazu poszczególnych typów nierelacyjnych baz danych, dodano również przykładowy model danych, implementację oraz charakterystyczne wady i zalety.
Klucz ? wartość
Model danych ma postać wielkiej skalowalnej HashMapy. Każdy pojedynczy element w bazie danych jest przechowywany jako nazwa atrybutu (?klucz?) wraz z jego wartością.
Za pomocą klucza klient ma możliwość uzyskania danej wartości, wstawić do niego nową wartość, bądź całkowicie taki klucz usunąć.
Wartość natomiast, jest polem typu ?blob?, które jest po prostu przechowywane, bez określania konkretnego typu danych (tak jak na ilustracji poniżej). Zrozumienie zawartości leży po stronie aplikacji.
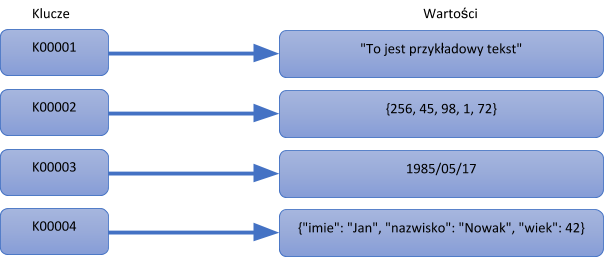
Zalety i wady:
| Zalety | Wady |
|---|---|
| Prostota modelu danych | Niezbyt dobrze sprawdza się przy złożonych danych |
| Wysoka skalowalność | Brak wsparcia dla obsługi powiązań między danymi |
| Duża odporność na błędy |
Przykład: Riak

Rozproszony magazyn danych charakteryzujący się wysoką dostępnością, prostotą obsługi i skalowalnością. Oprócz wersji open source jest on dostępny w obsługiwanej wersji korporacyjnej i wersji do przechowywania w chmurze. Riak ma niewrażliwą na uszkodzenia replikację danych i automatyczną dystrybucję danych w klastrze, co ma na celu zapewnienia wydajności i odporności.
Domyślna interakcja z bazą poprzez HTTP API:
- GET ? odczyt
- PUT ? aktualizacja, wstawianie (przy podaniu klucza)
- DELETE ? usuwanie
- POST ? wstawianie (generacja klucza po stronie bazy danych)
Inne przykłady: Aerospike, Apache Ignite, ArangoDB, BerkeleyDB, Couchbase, Dynamo, FairCom c-treeACE, FoundationDB, InfinityDB, LevelDB, MemcacheDB, MUMPS, Oracle NoSQL Database, OrientDB, Project Voldemort, Redis, Berkeley DB, SDBM/Flat File dbm, ZooKeeper
Dokumentowe
Jak nazwa wskazuje ich głównym elementem są dokumenty. Są to samoopisujące się, hierarchiczne struktury drzewiaste, przechowywane i zwracane przez bazę danych. Przykładowe formaty dokumentów:
- XML
- JSON
- BSON
Bazy dokumentowe są kolekcją dokumentów, które z kolei stanowią magazyn klucz ? wartość. Przechowywane dokumenty są z reguły porównywalne, ale nie muszą być koniecznie tożsame.
Przykładowe dokumenty (odpowiedniki wierszy w bazie relacyjnej):

Zalety i wady:
| Zalety | Wady |
|---|---|
| Prostota modelu danych | Niska jakość obsługi danych powiązanych ze sobą |
| Wysoka skalowalność | Słabo rozwinięty model odpytywania (klucze, indeksy) |
| Duże możliwości modelowania | MapReduce |
Przykład: MongoDB

Wieloplatformowy, nierelacyjny system do obsługi baz danych, stworzony w języku C++. Nie posiada ściśle określonej struktury obsługiwanych baz danych, zamiast tego używa dokumentów w formacie BSON (nieco podobnych do JSON, ale w binarnej postaci). Dzięki temu aplikacje mogą je bardziej naturalnie przetwarzać, przy zachowaniu możliwości tworzenia hierarchii oraz indeksowania.
Inne przykłady: Apache CouchDB, ArangoDB, BaseX, Clusterpoint, Couchbase, Cosmos DB, IBM Domino, MarkLogic, OrientDB, Qizx, RethinkDB
Grafowe
Bazy grafowe opierają się na przechowywaniu węzłów i krawędzi pomiędzy nimi. Węzeł jest odpowiednikiem encji, z kolei krawędzie odpowiadają relacjom. Przykładowy model można przedstawić w następujący sposób:
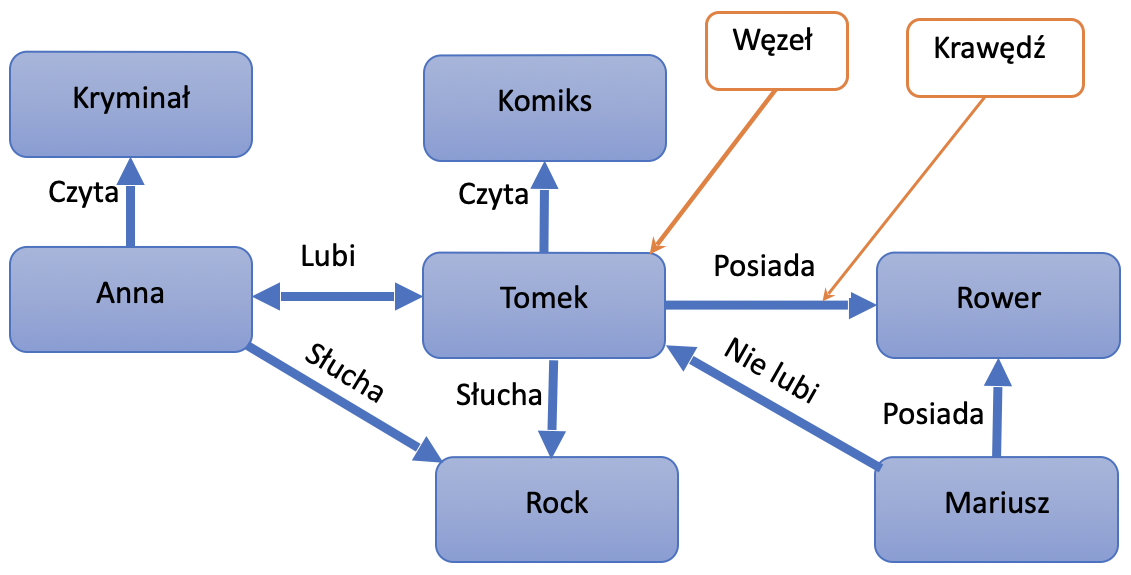
Zarówno węzły, jak i krawędzie posiadają swoje własności. Organizacja węzłów zgodnie z relacjami pozwala na znajdowanie pożądanych wzorców.
Zalety i wady:
| Zalety | Wady |
|---|---|
| Rozbudowany, ogólny model danych | Data sharding |
| Proste odpytywanie | Całkowita zmiana sposobu myślenia |
Przykład: Neo4J

Transakcyjna baza danych zgodna z ACID z natywnym przechowywaniem i przetwarzaniem grafów. Jedno z najpopularniejszych rozwiązań w kategorii grafowych baz danych.
Neo4j został zaimplementowany w Javie, jednak jest również dostępny z poziomu aplikacji napisanych w innych językach. Umożliwia to dedykowany język zapytań zwany Cypher, komunikujący się poprzez transakcyjny endpoint HTTP lub binarny protokół ?bolt?.
Inne przykłady: AllegroGraph, ArangoDB, InfiniteGraph, Apache Giraph, MarkLogic, OrientDB, Virtuoso
Kolumnowe (rodziny kolumn)
W przypadku baz rodziny kolumn, jak sama nazwa wskazuje, dane przechowywane są w formie rodziny kolumn ? grupy spokrewnionych danych, które zazwyczaj pobierane są razem. Te z kolei, przechowywane są w wierszach z przypisanymi kluczami.
Koncepcję tego typu bazy danych można przyrównać do ogromnej, zdemoralizowanej tabeli liczącej wiele wierszy i kolumn. Z tego względu są one głównie stosowane w sektorze VLDB (Very Large DataBase).
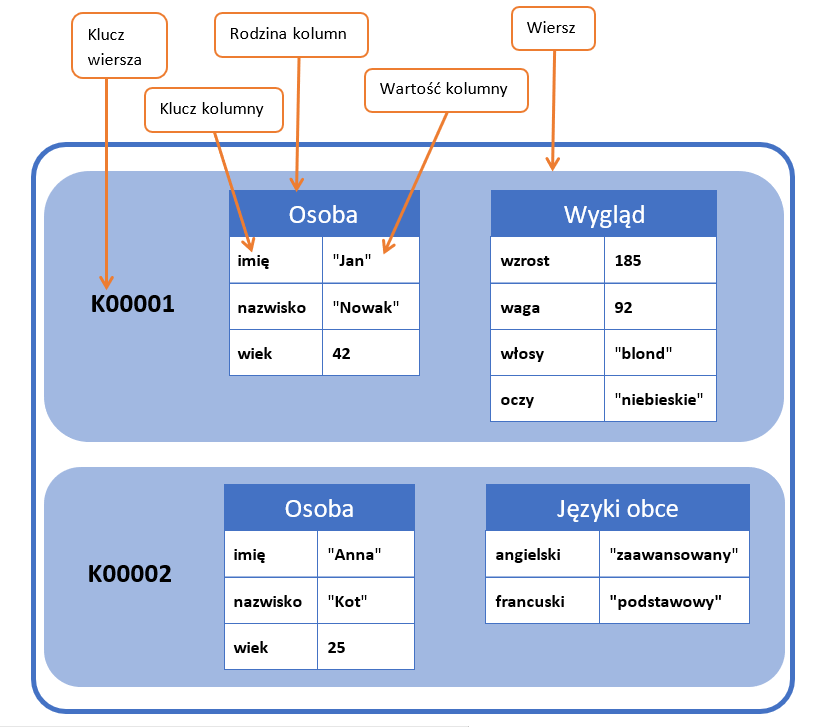
Zalety i wady:
| Zalety | Wady |
|---|---|
| Wsparcie dla danych półstrukturalnych | Brak wsparcia dla obsługi powiązań między danymi |
| Naturalne indeksowanie | Powolne operacje wierszowe (zwłaszcza te, obejmujące więcej niż jeden wiersz) |
| Wysoka skalowalność |
Przykład: Cassandra

Rozproszony system zarządzania bazą danych, zaprojektowany w celu obsługi dużej liczby rozproszonych danych na wielu serwerach. Operacje zapisu dokonywane są na całym klastrze, który nie posiada serwera głównego. Umożliwia to asynchroniczny odczyt i zapis danych, co przekłada się na minimalizację opóźnień.
Cassandra posiada język zapytań, o nazwie CQL (Cassandra Query Language). Wspiera on polecenia podobne do poleceń SQL.
Inne przykłady: Amazon SimpleDB, Accumulo, Druid, HBase, Hypertable, Vertica
Podsumowanie
Nie istnieje jeden wszechstronny model danych, który byłby remedium na wszystkie bolączki. Każdy z nich przedstawia odrębne, charakterystyczne dla siebie właściwości i znajduje zastosowanie w obszarze w którym sprawdzają się one najlepiej.
Wybór konkretnego rozwiązania powinien być dyktowany pożądanymi w danym systemie cechami bazy danych i problemami, przed którymi mają one ustrzec.
Powyższy artykuł daje możliwość zapoznania się z poszczególnymi modelami danych oraz ich konkretnymi implementacjami, co rzuca nieco światła na tą tematykę i daje ogólny obraz najpopularniejszych obecnie na rynku rozwiązań.
Źródła
- P. J. Sadalage, M. Fowler, ?NoSQL Kompendium wiedzy?, Helion 2015
- A. Wójcik, ?Nierelacyjne bazy danych?, Zeszyty Naukowe WSEI 2014
- https://www.geeksforgeeks.org/introduction-to-nosql/
- https://itwiz.pl/czym-jest-nosql-jak-wykorzystac-nierelacyjne-bazy-danych/
- https://riak.com/
- https://www.mongodb.com/
- https://neo4j.com/
- http://cassandra.apache.org/